A

Active-active or dual active infrastructure is a phrase used to describe a network of independent processing nodes where each node has access to a replicated database, giving each node access and usage of a single application. In an active-active system all requests are load-balanced across all available processing capacity. If a failure occurs on a node, another node in the network takes its place.
When multiple copies of an application are run in an environment, the environment is known as an active-active environment. With the advent of cloud infrastructure and related technology advances, active-active environments are much more feasible for organizations of any size.
In order to have an active-active application, you must first have active-active data centers. When you have the two together, you have the ability to deliver a new level of service called continuous availability.
Modern approaches to developing applications, including cloud based services and microservices, consider scalability as one of the essential design principles. An active-active environment provides cost efficiency thanks to the availability of cloud computing infrastructures and multi-tested open-source library sets.
B

Backup as a Service (BaaS) is a data backup approach that involves purchasing of backup and recovery services from an online backup service provider.
BaaS links systems to a private, public or hybrid cloud managed by an external service provider instead of managing backup through a centralized or on-premise IT department. BaaS allows backup administrators to not worry about maintenance of hard disks located outside the organization by transferring this responsibility to the service provider. BaaS can be used when the organization lacks the resources necessary for large amounts of backup. BaaS might allow the data to be accessible in case of a power failure or system malfunction, or to be recovered remotely.
Big Data is used to refer to massive, rapidly expanding and varied unstructured sets of digitized data. These massive data sets, which are difficult to maintain using traditional databases, are collected from multiple sources using a variety of methods.
Users leave behind digital traces from their online activities such as shopping and social media shares. These traces provide meaningful information to technologies of this new era, but this is just the tip of the iceberg. Big data can include digitized documents, photographs, videos, audio files, tweets and other social networking posts, e-mails, text messages, phone records, search engine queries, RFID tag and barcode scans and even financial transaction records. With advances in technology the numbers and types of devices that produce data have been proliferating as well. Besides home computers and retailers’ point-of-sale systems, we have Internet-connected smartphones, WiFi-enabled scales that tweet our weight, fitness sensors that track and sometimes share health related data, cameras that can automatically post photos and videos online and global positioning satellite (GPS) devices that can pinpoint our location on the globe, to name a few. Big data technology is essentially the analysis of all these digital traces collected from various devices and sources so that they can be used for intended purposes.
A Short History of Big Data
Available data has continuously increased throughout human history from earliest primal writings to the latest data centers. As data continuously accumulated to large amounts, complex data storage systems became necessary. Although big data has existed for a long time, for most people it has been a confusing subject. The biggest problem is to process big data. Humanity has developed certain methods to process data in accordance with their needs

In ancient Mesopotamia crops and herds information were recorded on clay tablets.
The earliest records of using data to track and control businesses date back to 7000 years ago when accounting was introduced in Mesopotamia in order to record the growth of crops and herds. Since then, methods of processing data has been developed for various reasons.
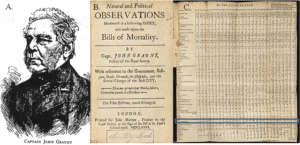
Natural and Political Observations Made upon the Bills of Mortality
In 1663, John Graunt recorded and examined all information about mortality roles in London. He wanted to gain an understanding and build a warning system for the ongoing bubonic plague. In the first recorded document of statistical data analysis, he gathered his findings in the book Natural and Political Observations Made upon the Bills of Mortality which provides great insights into the causes of death in the seventeenth century.

Herman Hollerith and The Tabulating Machine
American statistician invented a computing machine that could read holes punched into paper cards in order to organize census data in the 1890s. This machine allowed the census of United States of America to be completed in only one year instead of eight, and it spread across the world starting the modern data processing age.
The first major data project of the 20th century was created in 1937 and was ordered by the Franklin D. Roosevelt administration in the USA. After the Social Security Act became law in 1937, the government had to keep track of contributions from 26 million Americans and more than 3 million employers. IBM got the contract to develop a punch card-reading machine for this massive bookkeeping project.
The first data-processing machine appeared in 1943 and was developed by the British to decipher Nazi codes during World War II. This device, named Colossus, searched for patterns in intercepted messages at a rate of 5000 characters per second.

Colossus Computer
In 1965 the United Stated Government decided to build the first data center to store over 742 million tax returns and 175 million sets of fingerprints by transferring all those records onto magnetic computer tape that had to be stored in a single location. The project was never finished, but it is generally accepted that it was the beginning of the electronic data storage era.
Tim Berners, inventor of World Wide Web
In 1989, British computer scientist Tim Berners-Lee invented what is today known as the World Wide Web. He wanted to facilitate the sharing of information via a ‘hypertext’ system. Little did he know what the impact of his invention would be. As more and more devices were connected to the internet, big data sets began to form by 1990.
In 2005 Roger Mougalas from O’Reilly Media, a learning company established by Tim O’Reilly, coined the term big data for the first time, only a year after the company created the term Web 2.0. This was also the year that Yahoo! created Hadoop. It is an open-source software utilities platform used for data storage and processing data over a network of many computers. Nowadays Hadoop is used by many organizations to crunch through huge amounts of data.
In the past few years, there has been a massive increase in big data startups and more and more companies are slowly adopting big data. The increase in all things connected, led to a massive amount of data and the need for data scientists increased.
Advantages and Areas of Application of Big Data
The purpose of big data analytics is to analyze large data sets to help organizations make more informed decisions. These data sets might include web browser logs, clickstream data, social media content and network activity reports, text analytics of inbound customer e-mails, mobile phone call detail records and machine data captured by multi-sensors.
Organizations from different backgrounds invest in big data analytics to uncover hidden patterns, unknown correlations, market trends, customer preferences and other useful business information. Big data analytics are used across countless industries from the healthcare sector to education, media to the automotive industry, and even by Government.
Thanks to the benefits it provides big data has become a key technology of today:
- Identifying the root causes of failures and issues in real time
- Fully understanding the potential of data-driven marketing
- Generating customer offers based on their buying habits
- Improving customer engagement and increasing customer loyalty
- Reevaluating risk portfolios quickly
- Personalizing the customer experience
- Adding value to online and offline customer interactions
- Improving decision making processes
- Developing the education sector
- Optimizing product prices
- Improving recommendation engines
- Developing the healthcare sector
- Developing the agriculture industry
In the past people utilized cumbersome systems to extract, transform and load data into giant data warehouses. Periodically all the systems would backup and combine the data into a database where reports could be run. The problem was that the database technology simply could not handle multiple, continuous streams of data. The huge flow of data led to many problems such as not being able to handle the volume of data and modify incoming data in real time.
Big data solutions offer cloud hosting, highly indexed and optimized data structures, automatic archival and extraction capabilities, and reporting interfaces have been designed to provide more accurate analyses that enable businesses to make better decisions. Businesses started using big data technology that reduce costs through efficient sales and marketing, and better decision making intensively.

Business continuity is the ability of an organization to maintain essential functions during, as well as after, a disaster has occurred. Business continuity planning establishes risk management processes and procedures that aim to prevent interruptions to mission-critical services, and re-establish full function to the organization as quickly and smoothly as possible.
The most basic business continuity requirement is to keep essential functions up and running during a disaster and to recover with as little downtime as possible. A business continuity plan considers various unpredictable events, such as natural disasters, fires, disease outbreaks, cyber attacks and other external threats.
A business continuity plan has three key elements: Resilience, recovery and contingency.
A company can increase resilience by designing critical functions and infrastructures with various disaster possibilities in mind; this can include staffing rotations, data redundancy and maintaining a surplus of capacity. Ensuring resiliency against different scenarios can also help businesses maintain essential services on location and off-site without interruption.
Rapid recovery to restore business functions after a disaster is crucial. Setting recovery time objectives for different systems, networks or applications can help prioritize which elements need to be recovered first. Other recovery strategies include resource inventories, agreements with third parties to take on company activity and using converted spaces for mission-critical functions.
A contingency plan has procedures in place for a variety of external scenarios and can include a chain of command that distributes responsibilities within the organization. These responsibilities can include hardware replacement, leasing emergency office spaces, damage assessment and contracting third-party vendors for assistance.
Similar to a business continuity plan, disaster recovery planning specifies an organization’s planned strategies for post-failure procedures. However, a disaster recovery plan is just a subset of business continuity planning. Disaster recovery is mainly data focused, concentrating on storing data in a way that can be more easily accessed following a disaster. Business continuity takes this into account, but also focuses on the risk management, oversight and planning an organization needs to stay operational during a disruption.
C
CloudStack is an open-source infrastructure as a service (IaaS) platform that allows IT service providers to offer public cloud services. CloudStack can also be used by businesses that want to provide their own private cloud and hybrid clouds services on-premises. CloudStack includes a compute function that allocates virtual machines to individual servers, a network function that manages switches to create and manage logical networks, object and block storage systems, an image management function and a cloud computing management interface that supports all of the software stack’s components.
CloudStack allows administrators to deploy and manage large networks of virtual machines running the following hypervisors:
- VMware
- KVM
- Citrix XenServer
- Xen Cloud Platform (XCP)
- Oracle VM server
- Microsoft Hyper-V
CloudStack allows for features such as compute orchestration, resource management, user and account management, LDAP integration, MPLS support, storage tiering and single sign-on (SSO).

Cloud backup or online backup is a type of data backup whereby a copy of the data is sent over a secure proprietary or public network to a cloud based server. Cloud computing services are usually provided by a third-party vendor who sets the service fee based on scalability, bandwidth or number of users. Cloud data backup can be set up to run on demand, thus ensuring minimal data loss. The data is then available from various access points and can be shared among multiple cloud users.
Basically, the backup process entails copying data at the production site and transferring it to a remote storage system where it can be easily accessed. Many organizations choose cloud backup solutions for this purpose due to their high flexibility, easy deployment and on demand scalability.
To set up a cloud backup process a cloud backup service is purchased from the provider and is installed to the IT system, then files, folders, and applications to back up are chosen. Once the configuration is complete, the cloud backup system is ready for use. Most cloud backup providers allow you to set a backup schedule, operate with backup files, control allocated bandwidth and add new files if needed. Once the cloud backup service is customized, all data will be backed up automatically and continuously, requiring minimal input from the customer.
There are different approaches to cloud backup. These are:
Backing up directly to the public cloud: In this approach resources are duplicated in the public cloud. This method entails writing data directly to cloud providers, such as GlassHouse. The organization uses its own backup software to create the data copy to send to the cloud storage service. The cloud storage service then provides the destination and safekeeping for the data, but it does not specifically provide a backup application. In this scenario, it is important that the backup software is capable of interfacing with the cloud’s storage service. Additionally, with public cloud options, IT professionals may need to look into supplemental data protection procedures.
Backing up to a service provider: In this scenario, an organization writes data to a cloud service provider that offers backup services in a managed data center. The backup software that the company uses to send its data to the service may be provided as part of the service or the service may support specific commercially available backup applications.
Choosing a cloud-to-cloud (C2C) backup: As the name suggests, a cloud-to-cloud backup service copies data from one cloud to another cloud. The cloud-to-cloud backup service typically hosts the software that handles this process.
Using online cloud backup systems: There are also hardware alternatives that facilitate backing up data to a cloud backup service. These appliances are all-in-one backup machines. These appliances typically retain the most recent backup locally, saving transmission costs.
In addition to the various approaches to cloud backup, there are also multiple backup methods to consider. While cloud backup providers give customers the option to choose the backup method that best fits their needs and applications, it is important to understand the differences among the three main types below.
Full backups: The entire data is copied every time a backup is initiated, providing the highest level of protection. However, most organizations cannot perform full backups frequently because they can be time-consuming and take up too much storage capacity.
Incremental backups: Only data that has been altered or updated since the last backup is copied. This method saves time and storage space, but can make it more difficult to perform a complete restore. Incremental is a common form of cloud backup because it tends to use fewer resources.
Differential backups: Similar to incremental backups, these kinds of backups only contain data that has been altered since the last full backup, rather than the last backup in general. This method solves the problem of difficult restores that can arise with incremental backups.

Cloud computing is an overarching term that refers to providing large scale IT services such as servers, storage, databases, networks, software, information and analytics over the internet (cloud). Cloud computing is providing a wide array of IT services over the internet on a pay-per-use basis. The “cloud” term in cloud computing comes from the cloud symbol that is frequently used in flowcharts and diagrams to represent the internet.
Cloud servers are located in data centers all around the world. Organizations can have access to any kind of information technology ranging from applications to storage through a cloud service provider instead of having their own infrastructure or data centers. This provides users flexible resources, economic efficiency and the ability to innovate quickly.
A Short History of Cloud Computing
Cloud computing usually brings to mind products and ideas that first appeared in the 21st century, when in fact the emergence of this technology goes back to much earlier to the 1950s.
Around 1955 computer scientist John McCarthy who coined the term “artificial intelligence” puts forth the theory of sharing the information processing time that resembles cloud computing of today. Back then information processing cost a lot and small companies that did not have their own computers wanted to take advantage of information processing services without having to make a big investment. For this reason if users were able to find a way to share the computer they could have rented the computer in an efficient way without individually having to make a big purchase.
1970s witnessed the emergence of the virtual machine concept. It became possible to run more than one operating system at the same time in an isolated environment using virtualization software. Virtual machines took the main computer, which people share access over, to the next level and allow for many information processing environments to take place in a single physical environment. Virtualization led to important propulsion in the development of information processing technologies.
In the 1990s telecommunication companies started providing virtual private networks (VPN). In the past telecommunication companies only provided data links from one location to only one another. Thanks to these virtual private network connections these companies were able to provide users to share access over the same physical infrastructure instead of creating a physical infrastructure for each new user. Virtual private networks, just like the virtual machines, had an important contribution in the emergence of the cloud computing term.
By 1996 cloud computing, even though there have been some dispute about the term, was already a vibrant and growing asset for companies, educational institutions and information technologies. Later on cloud computing models and services have been developed to provide the best solution for various requirements.
Nowadays cloud computing takes place in the background of any system that uses an online service; whether one is sending an e-mail, processing a document or streaming TV and music. Even though only a short amount of time has passed since the introduction of cloud computing services, this technology is used in various areas ranging from small companies to global conglomerates, government institutions to non-profit organizations, satisfying the needs of its users.
How Does Cloud Computing Work?
A cloud computing system consists of two parts, back-end platform and the front-end. These two parts connect to each other over a network. The front-end is the part that the computer user or the customer sees. The server applications in the back-end are the “cloud” part of the system. The front-end includes the application that the customer needs to connect their computer or computer network to the cloud information processing system. Not all cloud computing systems share the same user interface. Services such as web-based e-mail applications use the available Web browser. Other systems have unique applications that allow clients network access.
At the back-end of the system are various computers, servers and data storage systems that form the “cloud” of the information services. In theory a cloud computing system can practically house any computer application ranging from data processing to video games. Usually each application will have its own server.
A central server manages the system and monitors the network traffic and client requests to ensure everything runs smoothly. It follows a sequence of rules known as protocol and uses special software called middleware. Middleware allows computers connected to the network to communicate with each other. Most times servers do not operate at full capacity. It is possible to operate a single physical server, as many servers that actually independently runs their own operating systems. This is called virtualization. Virtualization of servers maximizes the output of independent servers to reduce the need for more physical machines.
Advantages of Cloud Computing
In practice there are infinite areas of application for cloud computing. A cloud computing system can run any application that a normal computer runs with the help of the necessary middleware.
There are many reasons for the increasing popularity of cloud computing:
- Cloud computing allows users to access their applications and data at any time and place. Data is not limited to a hard disk on the user’s computer or the internal network of a company.
- Cloud computing systems reduce the advanced hardware requirements on the client’s side which might lead to reduced hardware costs. Thanks to cloud computing you do not require the fastest computer or the largest memory. Even a computer with an inexpensive computer terminal and basic input devices such as a monitor, keyboard and a mouse can provide enough processing power to run the middleware necessary to access the cloud system.
- Any company that takes advantage of IT services has to make sure to have the right software in order to reach its goals. Cloud computing systems allow companies to have company-wide access to such applications. This way companies do not have to purchase a software or license for each employee and instead pay a reasonable fee to the cloud computing company to continue their operations.
- Servers and digital storage devices require large physical spaces. Some companies rent physical spaces to store servers and databases. Thanks to cloud computing data can be stored in the cloud to achieve space-saving.

Cloud firewalls are software based, cloud deployed network devices, built to stop or mitigate unwanted access to private networks. As a new technology, they are designed for modern business needs and sit within online application environments. Because deployment is much simpler, organizations can adjust the size of their security solution without the frustrations inherent with on-site installation, maintenance and upgrading. As bandwidth increases, cloud firewalls can automatically adjust to maintain parity.
Cloud firewall providers account for the built-in cost of high availability by supporting infrastructure. This means guaranteeing redundant power, HVAC, and network services, and automating backup strategies in the event of a site failure.
Cloud firewalls can be reached and installed anywhere an organization can provide a protected network communication path.
A cloud firewall is capable of filtering traffic from a variety of sources. It’s capable of guaranteeing the security of connections made between physical data centers and the cloud. This is very beneficial for organizations looking for a means of migrating current solutions from an on-premise location to a cloud based infrastructure.
Cloud firewalls provide the same level of secure access as on-premise firewalls. This means advanced access policy, connection management, and filtering between clients and the cloud.
Cloud firewalls can integrate with access control providers and give users granular control over filtering tools.
Cloud firewalls provide tools for controlling performance, visibility, usage, configuration, and logging; all things normally associated with an on-premise solution.
All types of cloud firewalls are cloud based software that monitor all incoming and outgoing data packets, and filter this information against access policies with the goal of blocking and logging suspicious traffic.
Cloud migration is the process of moving digital business operations to the cloud. Cloud migration is sort of like a physical move, except it involves moving data, applications and IT processes from some data centers to other data centers, instead of packing up and moving physical goods. Much like a move from a smaller office to a larger one, cloud migration requires quite a lot of preparation and advance work.
There are different types of cloud migration a company can carry out. Commonly data and application are transferred from the internal data center of the company to the public cloud. On the other hand a cloud migration can transfer data and application from one cloud platform or provider to another cloud. This model is called cloud-to-cloud migration. A third type of migration is transferring data and application from a cloud back to a local data center in a reverse cloud migration.
The steps or processes an enterprise follows during a cloud migration vary based on factors such as the type of migration it wants to perform and the specific resources it wants to move. That said common elements of a cloud migration strategy include evaluating performance and security requirements, choosing a cloud provider, calculating costs and making any necessary organizational changes.
Common challenges an enterprise faces during a cloud migration include interoperability, data and application portability, data integrity and security, and business continuity. Without proper planning, a migration could negatively affect workload performance and lead to higher IT costs. This might negate some of the main benefits of cloud computing.
The general goal or benefit of any cloud migration is to host applications and data in the most effective IT environment possible, based on factors such as cost, performance and security.

Cloud service providers (CSP) are companies that provide network services, infrastructure or business applications over cloud. Cloud services are hosted in companies that operate over network connections or a data center that can be accessed by individual users. The cloud service provider provide certain components of cloud computing such as infrastructure as a service (IaaS), software as a service (SaaS) or platform as a service (PaaS) to companies and individuals.
In general, cloud service providers make their offerings available as an on demand purchase. Additionally, customers can pay for the cloud based services on a subscription basis. Some cloud service providers have differentiated themselves by tailoring their offerings to a vertical market’s requirements. Their cloud based services might seek to deliver industry-specific functionality or help users meet certain regulatory requirements. For instance, several healthcare cloud products have been released that let healthcare providers store, maintain and back up personal health information security.

Cloud storage is a cloud computing model that enables data storage management and operation as a service via a cloud computing service provider. It is delivered on demand with just-in-time capacity and costs. Cloud storage eliminates the need for companies to purchase and manage their own data storage infrastructure.
Cloud storage is purchased from a third party cloud provider through a pay-per-use model. Cloud storage providers manage the capacity, security and reliability of company data so that they can be accessed by applications.
Applications access cloud storage space through traditional storage protocols or directly via an API. Many cloud storage providers also provide supplementary services that allows for the large scale collection, management, protection and analysis of data.
Storing data in the cloud has these advantages for information technology departments:
- Total Cost of Ownership: Cloud computing allows for capacity expansion or reduction upon request and the quick change of performance and storage features, while only paying for the actually used storage space. Less frequently accessed data can be moved to lower cost tiered space automatically or through data auditing.
- Time to Deployment: Cloud computing provides just-in-time and on demand storage space. This allows IT specialists to focus on complex application problems instead of having to manage storage systems.
- Information Management: Centralizing storage in the cloud creates a tremendous leverage point for new use cases. By using cloud storage lifecycle management policies, you can perform powerful information management tasks including automated tiering or locking down data in support of compliance requirements.
There are three types of cloud data storage: object storage, file storage and block storage. Each offers their own advantages and has their own use cases.

Container in cloud computing is basically an approach to operating system virtualization. Container bundles the code of the application with dependencies in a standard software unit. Container in cloud computing is used to build blocks, which help in producing operational efficiency, version control, developer productivity and environmental consistency. Containers offer a logical packaging mechanism in which applications can be abstracted from the environment in which they actually run. By this, the user is assured of reliability, consistency and quickness regardless of the distributed platform.
Advantages of containers are as follows:
- The Consistency in Cloud Storage: The container enhances portability. It eliminates the organizational and technical frictions so that the program moves through the entire process cycle.
- Application Version Control: Through container in cloud computing, users can look at the current version of the application code as well as their dependencies. A manifest file is managed by the Docker containers. The users can easily hold and track the editions of container, look for differences between the container editions and roll-back to earlier versions if needed.
- Efficiency in the Operational Activities: The users can achieve more resources through container in cloud computing. By this, the users can also work at a time on several applications. Since each of the containers is a process of the operating system that works on an application and associated programs, the containers have a fast boot time.
- Productivity of the Developers: The containers deduct the dependencies and conflicts between the cross-service and thus the productivity increases. The component of the program is segregated into different entities that run a separate microservice. There is no worry about the libraries and dependencies that are being synced for each service because the containers are isolated from each other. Each service can be upgraded independently as they are not in touch with each other.
Container Automation is a critical component of building scalable and reliable solutions is cloud and container automation. Automation solves many technical challenges, enhances security and compliance, enables faster iteration, offers greater stability and can even improve customer perception of your product. Organizations must plan and execute a modern and reliable automation strategy for cloud and container needs.
Using cloud-native tools to implement full-environment automation for products and platforms builds a solid foundation for the infrastructure of cloud or on-premise environments.
Continuous data protection (CDP), also called continuous backup, is a storage system in which all the data in an enterprise is backed up whenever any change is made. In effect it creates an electronic journal of complete storage snapshots, one storage snapshot for every instant in time that data modification occurs. A major advantage of CDP is the fact that it preserves a record of every transaction that takes place in the enterprise. In addition, if the system becomes infected with a virus or trojan, or if a file becomes mutilated or corrupted and the problem is not discovered until sometime later, it is always possible to recover the most recent clean copy of the affected file. Installation of CDP hardware and programming is straightforward and simple and does not put existing data at risk.
Continuous data protection minimizes the amount of data that must be backed up within each cycle and effectively eliminates the backup window. As such, backups occur every few minutes, as opposed to once per night.
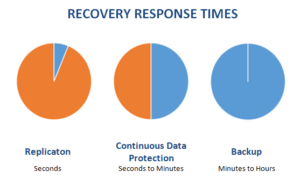
CDP works by incrementally backing up the changes in the state of the data over some period of time or when a record, file or block of information is created or updated. In some cases, there is only one initial full backup and all subsequent backups are incremental to the original backup. This approach is in contrast to the standard techniques for data backup, but has been gaining greater adoption. Continuous data protection systems can be block, file or application based.
Container Automation is a critical component of building scalable and reliable solutions is cloud and container automation. Automation solves many technical challenges, enhances security and compliance, enables faster iteration, offers greater stability and can even improve customer perception of your product. Organizations must plan and execute a modern and reliable automation strategy for cloud and container needs.
Using cloud-native tools to implement full-environment automation for products and platforms builds a solid foundation for the infrastructure of cloud or on-premise environments.
D

Data domain backup appliance is a hardware device equipped with backup management software, storage servers, network interfaces and other backup management support software. It operates by connecting to local components. Previously installed backup software captures data from the linked and structured device and stores this data in the local storage environment. The same data can be reinstalled via the storage device when required. It can also provide data security and protection services by encoding data.
Data domain backup appliance has rendered backups faster and easier to manage.
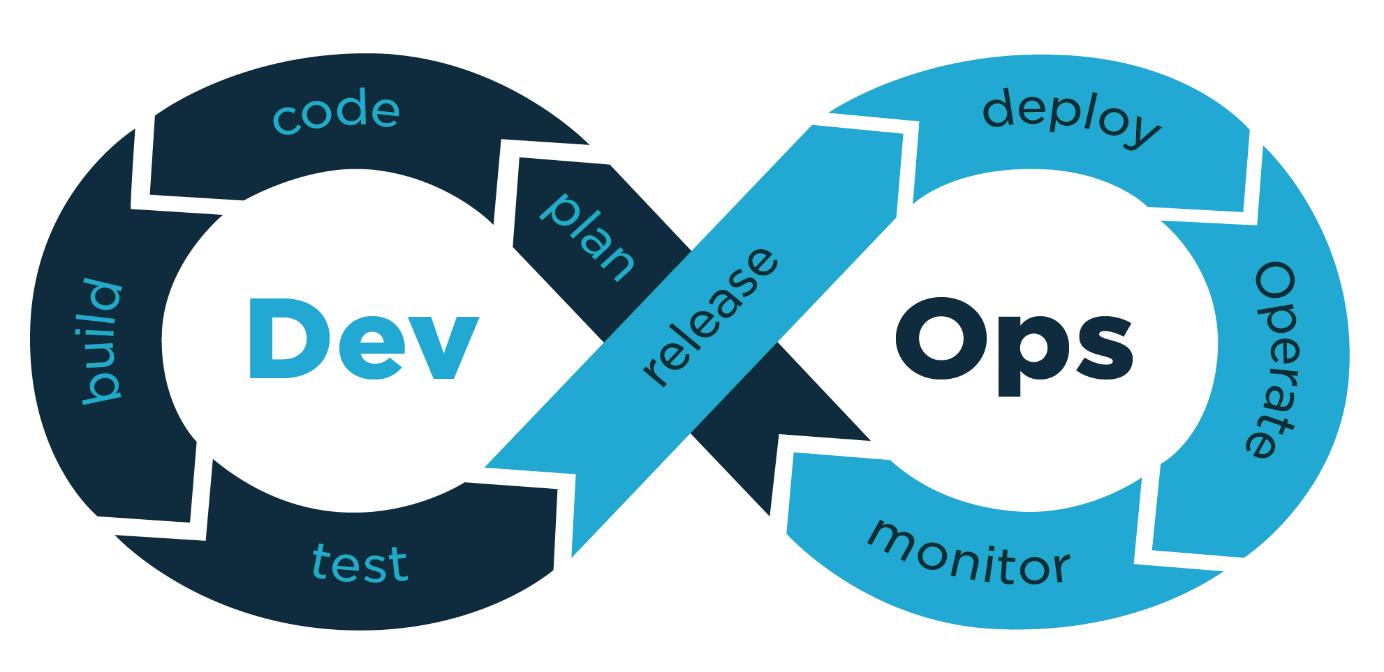
DevOps is a set of practices that automates the processes between software development and IT teams, in order that they can build, test and release software faster and more reliably. The concept of DevOps is founded on building a culture of collaboration between teams that historically functioned in separation. The promised benefits include increased trust, faster software releases, ability to solve critical issues quickly and better manage unplanned work. DevOps is a philosophy, a cultural approach. It emphasizes effective communication between the developers (Dev) and the system operators (Ops).
“Dev” usually refers to software developers, but in fact represent a larger group of people. This group includes anyone who works on the development of the software.
“Ops” is a wider concept compared to “Dev” and is used to refer to systems engineers, system administrators, release engineers, database administrators, network engineers, security specialists and other disciplines.
Nowadays, the speed at which software products (applications) change version (release) has increased and continues to increase with the rising competition between products. In this competition, companies and their products have to achieve quality results in order to satisfy their customers in a similar environment. Some companies offer dozens, maybe hundreds of software changes per day in real time to improve user experience, correct errors or add new features. That is why it has become inevitable to make software production with agility. In the past, the desired agility could not be achieved when “Dev” and “Ops” were working separately; companies that developed software were experiencing inefficiency and customers were not satisfied. Delayed projects, faulty products, unsuccessful version trials, wasted money and time, loss of reputation led to the need for DevOps.
DevOps Lifecycle
While the traditional software development lifecycle used to mainly follow the Waterfall methodology in the past, Agile SCRUM methodology has become widespread today. However, we can still see this lifecycle as a mixture of Agile, SCRUM and Waterfall methodologies in most organizations.
DevOps Lifecycle is as follows:
- The code is transferred to the source control system (check in)
- The code is pulled from the source control system to be compiled (pull)
- Tests are run. The continuous integration server generates builds and releases. Integration and user tests are performed
- The outputs that pass the tests (artifacts) and builds are stored
- Deployment is made using an automatic release tool
- Environment is configured
- Databases are updated
- Applications are updated
- Tested applications are transferred to users without them experiencing an interruption
- Application and network performance are monitored and problems are tried to be prevented before they occur
- Each step is repeated with some improvement
With DevOps, a continuous deployment of the products through a feedback cycle takes place through the following steps:
- Infrastructure Automation
- Configuration Management
- Deployment Automation
- Infrastructure Monitoring
- Log Management
- Application and Performance Management
Benefits of DevOps
The biggest change that comes with DevOps is that team members who used to work separately and have different skills, such as developers, database administrators, system administrators, system analysts, have come together to form a single team. This collaboration of different roles has many advantages. Continuous delivery, problems to be fixed being less complex and faster solutions to problems are the technical benefits of DevOps. Faster delivery of product features, more consistent and stable running systems, and spending time for improvement rather than troubleshooting are the business benefits of DevOps.

Cloud computing is an overarching term that refers to providing large scale IT services such as servers, storage, databases, networks, software, information and analytics over the internet (cloud). Cloud computing is providing a wide array of IT services over the internet on a pay-per-use basis. The “cloud” term in cloud computing comes from the cloud symbol that is frequently used in flowcharts and diagrams to represent the internet.
Cloud servers are located in data centers all around the world. Organizations can have access to any kind of information technology ranging from applications to storage through a cloud service provider instead of having their own infrastructure or data centers. This provides users flexible resources, economic efficiency and the ability to innovate quickly.
A Short History of Cloud Computing
Cloud computing usually brings to mind products and ideas that first appeared in the 21st century, when in fact the emergence of this technology goes back to much earlier to the 1950s.
Around 1955 computer scientist John McCarthy who coined the term “artificial intelligence” puts forth the theory of sharing the information processing time that resembles cloud computing of today. Back then information processing cost a lot and small companies that did not have their own computers wanted to take advantage of information processing services without having to make a big investment. For this reason if users were able to find a way to share the computer they could have rented the computer in an efficient way without individually having to make a big purchase.
1970s witnessed the emergence of the virtual machine concept. It became possible to run more than one operating system at the same time in an isolated environment using virtualization software. Virtual machines took the main computer, which people share access over, to the next level and allow for many information processing environments to take place in a single physical environment. Virtualization led to important propulsion in the development of information processing technologies.
In the 1990s telecommunication companies started providing virtual private networks (VPN). In the past telecommunication companies only provided data links from one location to only one another. Thanks to these virtual private network connections these companies were able to provide users to share access over the same physical infrastructure instead of creating a physical infrastructure for each new user. Virtual private networks, just like the virtual machines, had an important contribution in the emergence of the cloud computing term.
By 1996 cloud computing, even though there have been some dispute about the term, was already a vibrant and growing asset for companies, educational institutions and information technologies. Later on cloud computing models and services have been developed to provide the best solution for various requirements.
Nowadays cloud computing takes place in the background of any system that uses an online service; whether one is sending an e-mail, processing a document or streaming TV and music. Even though only a short amount of time has passed since the introduction of cloud computing services, this technology is used in various areas ranging from small companies to global conglomerates, government institutions to non-profit organizations, satisfying the needs of its users.
How Does Cloud Computing Work?
A cloud computing system consists of two parts, back-end platform and the front-end. These two parts connect to each other over a network. The front-end is the part that the computer user or the customer sees. The server applications in the back-end are the “cloud” part of the system. The front-end includes the application that the customer needs to connect their computer or computer network to the cloud information processing system. Not all cloud computing systems share the same user interface. Services such as web-based e-mail applications use the available Web browser. Other systems have unique applications that allow clients network access.
At the back-end of the system are various computers, servers and data storage systems that form the “cloud” of the information services. In theory a cloud computing system can practically house any computer application ranging from data processing to video games. Usually each application will have its own server.
A central server manages the system and monitors the network traffic and client requests to ensure everything runs smoothly. It follows a sequence of rules known as protocol and uses special software called middleware. Middleware allows computers connected to the network to communicate with each other. Most times servers do not operate at full capacity. It is possible to operate a single physical server, as many servers that actually independently runs their own operating systems. This is called virtualization. Virtualization of servers maximizes the output of independent servers to reduce the need for more physical machines.
Advantages of Cloud Computing
In practice there are infinite areas of application for cloud computing. A cloud computing system can run any application that a normal computer runs with the help of the necessary middleware.
There are many reasons for the increasing popularity of cloud computing:
- Cloud computing allows users to access their applications and data at any time and place. Data is not limited to a hard disk on the user’s computer or the internal network of a company.
- Cloud computing systems reduce the advanced hardware requirements on the client’s side which might lead to reduced hardware costs. Thanks to cloud computing you do not require the fastest computer or the largest memory. Even a computer with an inexpensive computer terminal and basic input devices such as a monitor, keyboard and a mouse can provide enough processing power to run the middleware necessary to access the cloud system.
- Any company that takes advantage of IT services has to make sure to have the right software in order to reach its goals. Cloud computing systems allow companies to have company-wide access to such applications. This way companies do not have to purchase a software or license for each employee and instead pay a reasonable fee to the cloud computing company to continue their operations.
- Servers and digital storage devices require large physical spaces. Some companies rent physical spaces to store servers and databases. Thanks to cloud computing data can be stored in the cloud to achieve space-saving.

Docker is an open-source environment of product containers. These containers help applications to work while they are being shifted from one platform to another. This is a new era technology, which enables enterprises to ship, build, and run any product from any geolocation. It is true that several problems are associated with hosting environments and this Docker technology tries to fix those issues by the creation of a standardized way to distribute and scale the apps. In the current scenario, Docker has become popular among different cloud architecture machines. It permits applications to be bundled and copied where all apps are dependent on each other. Cloud users find this concept useful when it comes to working with a scalable infrastructure. When Docker gets integrated with cloud, it is named as Docker Cloud.
Docker differs from virtual machines by eliminating worries about which operating system is used. Docker enables the virtualization of the operating system itself with the application and every connected component.
- It is portable and works anywhere.
- It allows for strong and weak scaling.
- Due to lower workload density more containers can be housed in a single machine.
- Easy installation on clouds and on-premises.
blocking and logging suspicious traffic.

Docker Compose is a tool for defining and running multi-container Docker applications. With applications getting larger and larger as time goes by, it gets harder to manage them in a simple and reliable way. That is where Docker Compose comes into play. Docker Compose allows developers to write a YAML configuration file for application service which then can be started using a single command.
Docker Compose enables to bring up a complete development environment with only one command. This allows developers to keep development environment in one central place and easily deploy applications.
Another great feature of Compose is its support for running unit and end-to-end tests in a quick a repeatable fashion by putting them in their own environments. That means that instead of testing the application on your local/host operating system, you can run an environment that closely resembles the production circumstances.
Compose uses project names to isolate environments from each other bringing the benefits of running multiple copies of the same environment on one machine and preventing different projects and service from interfering with each other.

Disaster recovery as a Service (DRaaS) is a cloud computing and backup service model that uses cloud resources to protect applications and data from disruption caused by disaster. It gives an organization a total system backup that allows for business continuity in the event of system failure.
DRaaS is often offered in conjunction with a disaster recovery plan (DRP) or business continuity plan (BCP). DRaaS is also known as business continuity as a service (BCaaS).
DRaaS enables the full replication and backup of all cloud data and applications while serving as a secondary infrastructure. It actually becomes the new environment and allows an organization and users to continue with daily business processes while the primary system undergoes repair. DRaaS allows these applications to run on virtual machines at any time, even without a real disaster.
E

Dell EMC NetWorker is designed to back up data from a variety of systems across an organization.
Dell EMC NetWorker offers support for Windows, Mac OS, OpenVMS and Linux/Unix operating systems. The software can also protect application data on platforms such as Oracle, SAP, Lotus, Informix, Sybase, Microsoft Exchange Server, SharePoint and SQL Server, using application-specific plug-ins. NetWorker is integrated with Dell EMC’s Data Domain and Dell EMC Avamar storage systems for data deduplication, and NetWorker PowerSnap module allows users to create policy based point-in-time snapshots using Dell EMC storage arrays.
The benefits of NetWorker are as follows:
- Centralized control for all backup requirements.
- Protect mission critical business applications, operating systems and storage.
- Centrally manage one or more backup servers with web-based NetWorker Management Console.
- Integration with the industry’s two leading deduplication solutions EMC Avamar and EMC Domain.
- Eliminates redundant data, speeds backups, simplifies replication and streamlines management.
- Optimized protection for leading virtualization platforms including VMware vSphere and Microsoft Hyper-V.
- Deduplication reduces impact of data protection operations on virtual environment.
- Perform online backup while enabling both disaster and operational recovery.
- Enterprise-class scalability & security.
H

Hybrid Cloud is a cloud computing environment that uses a mix of private cloud and public cloud services with orchestration between the two platforms. By allowing workloads to move between private and public clouds as computing needs and costs change, hybrid cloud gives businesses greater flexibility and more data deployment options.
Establishing a hybrid cloud requires the availability of a public infrastructure as a service (IaaS) platform such as GlassHouse Cloud, a private cloud constructed with the help of a cloud service provider and adequate wide area network (WAN) connectivity between these two environments.
Typically, an enterprise will choose a public cloud to access compute instances, storage resources or other services, such as big data analytics clusters or serverless compute capabilities. However, an enterprise has no direct control over the architecture of a public cloud, so, for a hybrid cloud deployment, it must architect its private cloud to achieve compatibility with the desired public cloud or clouds. This involves the implementation of suitable hardware within the data center including servers, storage, a local area network (LAN) and load balancers. An enterprise must then deploy a virtualization layer or a hypervisor to create and support virtual machines and, in some cases, containers. Then IT teams must install a private cloud software layer such as OpenStack on top of the hypervisor to deliver cloud capabilities such as self-service, automation and orchestration, reliability and resilience, and billing and chargeback.
The key to create a successful hybrid cloud is to select hypervisor and cloud software layers that are compatible with the desired public cloud, ensuring proper interoperability with that public cloud’s application programming interfaces (APIs) and services. The implementation of compatible software and services also enables instances to migrate seamlessly between private and public clouds. A developer can also create advanced applications using a mix of services and resources across the public and private platforms.
Hybrid cloud is also particularly valuable for dynamic workloads. For example, a transactional order entry system that experiences significant demand spikes around the holiday season is a good hybrid cloud candidate. The application could run in private cloud, but use cloud bursting to access additional computing resources from a public cloud when computing demands spike.
Another hybrid cloud use case is big data processing. A company, for example, could use hybrid cloud storage to retain its accumulated business, sales, test and other data, and then run analytical queries in the public cloud, which can scale a Hadoop or other analytics cluster to support demanding distributed computing tasks.
Hybrid cloud also enables an enterprise to use broader mix of IT services. For example, a business might run a mission-critical workload within a private cloud, but use the database or archival services of a public cloud provider.
Businesses from various sectors have gravitated towards hybrid cloud solutions to reduce costs and decrease the workload on on-premise resources. Across sectors ranging from finance to healthcare, hybrid cloud has not only improved information processing and storage power, but at the same time effectively optimized the requirement for physical space.

Hypervisor is virtual machine monitor (VMM) that enables numerous virtual operating systems to simultaneously run on a computer system. These virtual machines are also referred to as guest machines and they all share the hardware of the physical machine like memory, processor, storage and other related resources. This improves and enhances the utilization of the underlying resources.
The hypervisor isolates the operating systems from the primary host machine. The job of a hypervisor is to cater to the needs of a guest operating system and to manage it efficiently. Each virtual machine is independent and do not interfere with each another although they run on the same host machine. Even at times when one of the virtual machines crashes or faces any issues, the other machines continue to perform normally.
There are two major classifications of hypervisors to be aware of. Type-1 and Type-2 both do the same basic task, but the way they do it is quite different from each other.
Type-1 hypervisors run directly on the hardware. In other words they require no software or operating systems to be installed ahead of time and install right onto the hardware you want to run them on. Hyper-V Server and ESXi are two examples of this type of hypervisor that is used in many places today. The benefit of a Type-1 hypervisor is direct access to the physical hardware.
While type-1 hypervisors are very powerful, they are complex platforms that require a great deal of specialized knowledge to run. They also tend to have strict hardware requirements to run properly. Although they are perfect for IT operations, they are not the best fit for casual configurations or desktop work. The second type of hypervisor fills this gap.
Type-2 hypervisors are designed to install onto an existing operating system. They tend to have a much lower learning curve, and require far less in terms of hardware horsepower to function, but this comes at a price. Type-2 hypervisors typically cannot run more complex virtual workloads or high-utilization workloads within virtual machines. They’re designed for basic development, testing and emulation tasks such as running Windows software on a Mac.
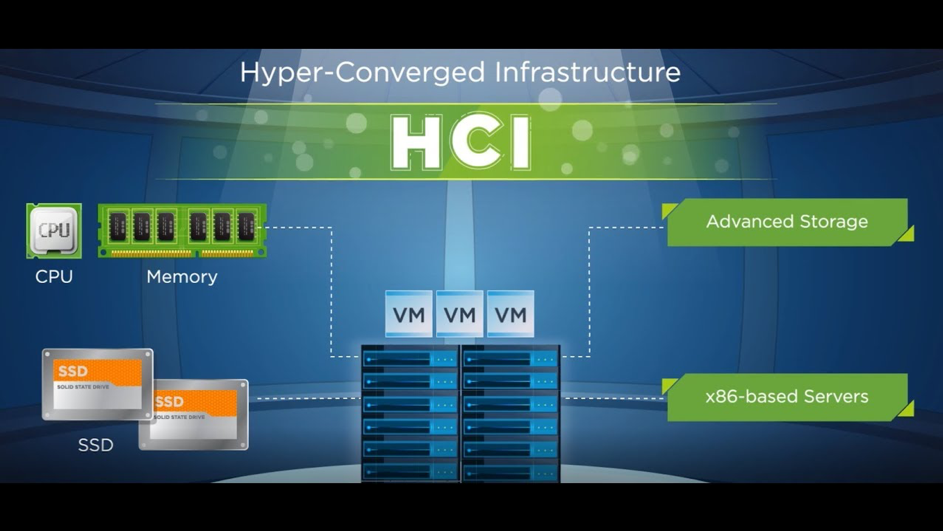
Hyper-converged Infrastructure (HCI) combines common datacenter hardware using locally attached storage resources with intelligent software to create flexible building blocks that replace legacy infrastructure consisting of separate servers, storage networks, and storage arrays. Benefits include lower total cost of ownership, increased performance and greater productivity within IT teams. This simplified solution uses software and servers to replace expensive, purpose-built hardware. With hyper-converged infrastructure, you will decrease data center complexity and increase scalability.
Hyper-converged Infrastructure converges the entire datacenter stack, including compute, storage, storage networking and virtualization. Complex and expensive legacy infrastructure is replaced by a platform running on turnkey, industry-standard servers that enable enterprises to start small and scale one node at a time. Software running on each server node distributes all operating functions across the cluster for superior performance and resilience.
- All critical data center functions run on a tightly integrated software layer, as opposed to purpose-built hardware.
- The virtualization software abstracts and pools the underlying resources, then dynamically allocates them to applications running in virtual machines or containers.
- Configuration is based on policies aligned with the applications, eliminating the need for complicated constructs like logical unit numbers and volumes.
- Advanced management features further reduce manual tasks and help automate entire operations.
Hyper-converged Infrastructure consists of two main components, the distributed plane and the management plane.
The distributed plane runs across a cluster of nodes delivering storage, virtualization and networking services for guest applications, whether they’re virtual machines or container-based apps.
The management plane lets you easily administer HCI resources from one place and one view, which eliminates the need for separate management solutions for servers, storage networks, storage and virtualization.
Enterprise IT teams today are looking for ways to deliver on-premise IT services with the speed and operational efficiency of public cloud services such as Amazon Web Services (AWS), Microsoft Azure and Google Cloud. A comprehensive enterprise cloud platform bridges the gap between traditional infrastructure and public cloud services—and hyper convergence is at the core of an enterprise or hybrid cloud.
Making the switch from the complex legacy infrastructure to the simplicity of hyper convergence provides lower costs, improved performance and greater productivity in IT teams.
I

Infrastructure as a Service (IaaS) is a form of cloud computing that provides virtualized computing resources over the internet. IaaS is one of the three main categories of cloud computing services, alongside software as a service (SaaS) and platform as a service (PaaS). In the IaaS model, third-party service providers host hardware equipment, operating systems and other software, servers, storage systems and various other IT components for customers in a highly automated delivery model. In some cases, IaaS providers also handle tasks such as ongoing systems maintenance, data backup and business continuity.
In an IaaS model, a cloud provider hosts the infrastructure components traditionally present in an on-premise data center including servers, storage and networking hardware, as well as the virtualization or hypervisor layer. The IaaS provider also supplies a range of services to accompany those infrastructure components. These can include detailed billing, monitoring, log access, security, load balancing and clustering, as well as storage resiliency such as backup, replication and recovery. These services are increasingly policy-driven, enabling IaaS users to implement greater levels of automation and orchestration for important infrastructure tasks.
IaaS customers access resources and services through a wide area network (WAN) such as the internet and can use the cloud provider’s services to install the remaining elements of an application stack. For example, the user can log in to the IaaS platform to create virtual machines. Customers can then use the provider’s services to track costs, monitor performance, balance network traffic, troubleshoot application issues, manage disaster recovery and more.
Any cloud computing model requires the participation of a provider. The provider is often a third-party organization that specializes in selling IaaS. IaaS provides the users with many advantages:
- Scalability: One of the main benefits of IaaS is the scalability it offers. Through a subscription service, you access the IT system you require when you need it. Due to its virtualization, scaling up your systems can be done quickly and efficiently, minimizing downtime.
- Minimized hardware maintenance: The hardware behind your IaaS system is managed externally, minimizing the time and money your business spends on this type of maintenance.
- Flexibility: Many IaaS systems can be accessed remotely, although this will vary from system to system.
- Reduced downtime: If your hardware fails, you will usually need to wait for a repair, impacting the productivity of both your staff and business overall.
On demand access: An IaaS system can be accessed on demand and you will only pay for the resources you use, keeping costs down.

Internet of Things (IoT), in simple terms, refers to an ongoing trend of connecting all kinds of physical objects to the internet. These devices can be anything from common household objects like refrigerators and light bulbs, to automobiles and traffic lamps. More specifically, IoT refers to any system of physical devices that receive and transfer data over wireless networks. In the Internet of Things approach objects are integrated with sensors to collect data from their environment and transfer this data to other objects over the network. For example, the collection of health related data from a smart watch and transferring it to the smart phone over the network is an Internet of Things approach. The watch and the phone are the objects in this instance and these two objects are connected. Devices equipped with sensors and that can communicate over the network are called smart devices. Nowadays Internet of Things is used in many areas from healthcare to agriculture, manufacturing and education.
A Brief History of the Internet of Things
Machines have been providing direct communications from the time of the telegraph, which was developed in the 1830s. Described as “wireless telegraphy,” the first radio voice broadcast took place on 3rd June 1900, providing another necessary element for developing the Internet of Things. The development of computers began in the 1950s.
The Internet, itself a significant component of the IoT, started out as part of DARPA (Defense Advanced Research Projects Agency) in 1962 and evolved into ARPANET in 1969. In the 1980s, commercial service providers started supporting public use of ARPANET, enabling it to develop into our modern Internet. Global Positioning Satellites (GPS) became a reality in the year 1993, with the Department of Defense providing a solid, highly functional system of 24 satellites. This was quickly replaced by privately owned, commercial satellites being placed in earth’s orbit. Satellites and landlines provide basic communications for much of the IoT.
One of the very first examples of an Internet of Things is from the early 1980s that was a Coca Cola machine, located at Carnegie Mellon University. Local programmers would connect through the internet to the refrigerated appliance and check to see if there was a drink available and if it was cold.
The concept of Internet of Things was not named until 1999. Kevin Ashton, the Executive Director of Auto-ID Labs at MIT, was the very first to describe the Internet of Things while preparing a presentation for Procter & Gamble. He named his 1999 presentation the Internet of Things after the trending technology of the day, the internet. Kevin Ashton thought Radio Frequency Identification (RFID) was a requirement for the Internet of Things. He decided that if all devices were “tagged,” computers could manage, track, and check them. Although Kevin’s presentation attracted the attention of some P&G executives, the term Internet of Things was not a matter of interest for the next 10 years.
In 2010, Chinese government declared Internet of Things a strategic priority in its five year plan.
By the year 2013, the Internet of Things had evolved into a system using multiple technologies. The casual fields of automation (including the automation of buildings); wireless detector networks, GPS, control systems, and others, all support the IoT.
Advantages of the Internet of Things
The internet of things helps people live and work smarter. IoT provides businesses with a real time look into how their companies’ systems really work. IoT enables companies to automate processes and reduce labor costs. It also cuts down on waste and improves service delivery, making it less expensive to manufacture and deliver goods as well as offering transparency into customer transactions. IoT touches every industry, including healthcare, finance, retail and manufacturing. For example, smart cities help citizens reduce waste and energy consumption and connected sensors are even used in farming to help monitor crop and cattle yields and predict growth patterns. As such, IoT is one of the most important technologies of everyday life. IoT, by providing advantages through integration with other technologies of the day such as artificial intelligence, robotics and augmented reality, becomes even more popular with each passing day.
K

Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, which facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support and tools are widely available.
The name Kubernetes originates from Greek, meaning helmsman or pilot. Google open-sourced the Kubernetes project in 2014.
Traditional deployment era: Early on, organizations ran applications on physical servers. There was no way to define resource boundaries for applications in a physical server and this caused resource allocation issues. For example, if multiple applications run on a physical server, there can be instances where one application would take up most of the resources and as a result the other applications would underperform. A solution for this would be to run each application on a different physical server. But this did not scale as resources were underutilized and it was expensive for organizations to maintain many physical servers.
Virtualized deployment era: Virtualization was introduced as a solution for traditional deployment. It allows running multiple Virtual Machines on a single physical server’s CPU, which allows applications to be isolated between virtual machines. This provides a level of security as the information of one application cannot be freely accessed by another application.
Container deployment era: Containers are similar to virtual machines, but they have relaxed isolation properties to share the operating system among the applications. Similar to a virtual machine, a container has its own file system, CPU, memory, process space and more. As they are decoupled from the underlying infrastructure, they are portable across clouds and operating system distributions.
Containers are a good way to bundle and run your applications. In a production environment, you need to manage the containers that run the applications and ensure that there is no downtime. This is where Kubernetes enters the equation. Kubernetes provides you with a framework to run distributed systems resiliently. It takes care of scaling and failover for your application and provides deployment patterns and more.
- Kubernetes can expose a container using the DNS name or using their own IP address. If traffic to a container is high, Kubernetes is able to load balance and distribute the network traffic so that the deployment is stable.
- Kubernetes allows you to automatically mount a storage system of your choice, such as local storages, public cloud providers and more.
- You can describe the desired state for your deployed containers using Kubernetes and it can change the actual state to the desired state at a controlled rate. For example, you can automate Kubernetes to create new containers for your deployment, remove existing containers and adopt all their resources to the new container.
- Kubernetes restarts containers that fail, replaces containers, kills containers that do not respond to your user-defined health check.
L
Layer 2 and Layer 3 refer to different parts of IT network communications. The ‘layers’ refer to how you configure an IT network, and the standard for network communications called the Open System Interconnection (OSI) model.
Layer 2 is a broadcast Media Access Control (MAC) level network, while Layer 3 is a segmented routing over internet protocol (IP) network.
OSI is a networking model comprised of seven ‘layers’. It’s a controlled hierarchy where information is passed from one layer to the next creating a blueprint for engineers to organize communication.
Layer 2 is the data link where data packets are encoded and decoded into bits. The MAC sub layer controls how a computer on the network gains access to the data and permission to transmit it and the LLC (Logical Link control) layer controls frame synchronization, flow control and error checking.
Layer 3 provides switching and routing technologies, creating logical paths, known as virtual circuits, for transmitting data from node to node. Routing and forwarding are functions of this layer, as well as addressing, internetworking, error handling, congestion control and packet sequencing.
Load balancer is a device that acts as a reverse proxy and distributes network or application traffic across a number of servers. Load balancers are used to increase capacity and reliability of applications. They improve the overall performance of applications by decreasing the burden on servers associated with managing and maintaining application and network sessions, as well as by performing application-specific tasks.
Load balancers are generally grouped into two categories: Layer 4 and Layer 7. Layer 4 load balancers act upon data found in network and transport layer protocols (IP, TCP, FTP, UDP). Layer 7 load balancers distribute requests based upon data found in application layer protocols such as HTTP. Requests are received by both types of load balancers and they are distributed to a particular server based on a configured algorithm.
M

Monitoring as a Service (MaaS) is a framework that facilitates the deployment of monitoring functionalities for various other services and applications within the cloud. The most common application for MaaS is online state monitoring, which continuously tracks certain states of applications, networks, systems, instances or any element that may be deployable within the cloud.
MaaS offerings consist of multiple tools and applications meant to monitor a certain aspect of an application, server, system or any other IT component. There is a need for proper data collection, especially of the performance and real time statistics of IT components, in order to make proper management possible.
The tools being offered by MaaS providers may vary in some ways, but there are very basic monitoring schemes that have become ad hoc standards simply because of their benefits. State monitoring is one of them and it has become the most widely used feature. It is the overall monitoring of a component in relation to a set metric or standard. In state monitoring, a certain aspect of a component is constantly evaluated and results are usually displayed in real time or periodically updated as a report.

Memory is the internal storage areas within computing systems. The computer memory is any physical device that can temporarily store data such as RAM (random access memory) or ROM (read only memory). Some computers also make use of virtual memory that expands the physical memory via the hard disk. Memory devices operate through integrated circuits and are used by operating systems, software and hardware.
Memory can be classified as temporary or permanent. Temporary memory does not store data when the computer or the hardware device is no longer powered. Computer RAM is an example of temporary memory. This is why if the computer freezes or restarts while you are working, data that has not been saved might be lost. Permanent memory, sometimes abbreviated as NVRAM, is a type of memory that stores the data even in the case of a loss of power. EPROM is another example for permanent memory. Virtual memory is the memory management capability of an operating system that uses hardware and software to temporarily transfer data from the random access memory (RAM) to the hard disk in order to compensate for insufficient physical memory. Virtual address spaces use active memory of the RAM and the inactive memory of the hard disk drives (HDD) to make available addresses that are contiguous that can store both the application and the data.
Memory is usually categorized as cache, primary and secondary:
Cache memory is very high speed and semiconductor based, it can improve the performance of the central processing unit (CPU). It serves as a buffer between the CPU and the primary memory. It is used to store data and application instructions most frequently requested by the CPU. Operating systems transfer data and parts of an application from the disk to the cache where the CPU can access them.
Primary memory (main memory) only stores data and instructions that are currently used by the computer. It has a limited capacity and data is lost when the power supply is switched off. It is usually comprised of a semiconductor device. Data and instructions that need to be processed are stored in the main memory. It has two sub-categories as RAM and ROM.
Secondary memory is known as external memory as well. CPU does not access this memory directly, instead it uses input/output channels for indirect access. The data stored on secondary memory is first transferred to the main memory, upon which it can be accessed by the CPU. CD-ROM, DVD and similar devices are examples of secondary memory.
Multicloud is a strategy where an organization leverages two or more cloud computing platforms to perform various tasks. Organizations that do not want to depend on a single cloud provider may choose to use resources from several providers to get the best benefits from each unique service. A multicloud solution may refer to the combination of software as a service (SaaS), platform as a service (PaaS) and infrastructure as a service (IaaS) models.
Multicloud strategy can include the use of a hybrid environment but relies on more than one public cloud. The strategy may reduce the need for cloud migration, as some data can remain on the enterprise’s servers.
Some cloud environments may be tailored for specific use cases, which prompt IT stakeholders to select specific cloud service providers for various business functions. Organizations choose multicloud strategies for a number of reasons. Some leaders want to avoid dependence on a single cloud provider, thereby reducing financial risk. Getting stuck with a single vendor could make it difficult for an organization to adopt a responsive strategy. Other organizations decide upon a multicloud strategy to mitigate the risk of a localized hardware failure. Such a failure in an on-site data center could push the entire enterprise offline. Multicloud greatly reduces the risk of catastrophic failure. Multicloud provides organizations with more options that provide the ability to invest in digital transformation without getting locked into a single service or putting down a huge outlay of capital.
A multicloud strategy allows stakeholders to pick and choose the specific solutions that work best for their organization. As diverse business needs arise, change and become more complex, the business can allocate resources for specific uses, maximize those resources and pay for only what they use.
Multicloud also reduces the risk that a distributed denial of service (DDoS) attack could take mission-critical applications offline. When even a single hour of downtime can cost an organization thousands, advanced security protocols pay for themselves.
N

Network Operation Center (NOC) is a central location where network administrators control and monitor one or more networks. Its main purpose is to manage optimal network activities across various platforms, environments and communication channels.
A network operation center monitors power failures, communication line warnings and other performance areas that might affect the network. In addition to large institutions with large networks, network service providers also have a network operation center, a room in which the visualization of the network or the networks that are monitored, workstations that show details of the network status and the necessary software are present. Network operation center is the focal point for troubleshooting network problems, distributing and upgrading software, managing router and domain name, monitoring performance and coordinating with connected networks. Technical teams at the network operation center carefully keep track of the endpoints they monitor and manage, independently troubleshoot manifesting problems and take measures to prevent problems. Engineers and technicians at a network operation center are responsible from monitoring the condition, safety and capacity of the infrastructure. They take decisions to optimize network performance and institutional efficiency, then implement the necessary measures. Network operation center technicians categorize a problem under certain tags in terms of its significance, type and other criteria when any action or response is requested from the administrative service provider. Depending on the organizational relationship between the network operation center and the administrative service provider, the technical teams might work together to solve the problem and identify the underlying issues to prevent future problems.
Network operation centers have these additional capacities:
- Application software installation, troubleshooting and upgrade
- E-mail management services
- Backup and storage management
- Network discovery and assessment
- Policy configurations
- Firewall and intrusion prevention system monitor and management
- Virus prevention, detection and removal
- Patch management and whitelisting
- Threat analysis
- Optimization and service quality reports
- Voice and video traffic management
- Performance reports and improvement suggestions
O
OpenStack is a set of software tools for building and managing cloud computing platforms for public and private clouds. It is backed by some of the biggest companies in software development and hosting, as well as thousands of individual community members. OpenStack is managed by the OpenStack Foundation, a non-profit that oversees both development and community-building around the project.
OpenStack lets users deploy virtual machines and other instances that handle different tasks for managing a cloud environment on the fly. It makes horizontal scaling easy.
OpenStack is open-source software, which means that anyone who chooses to can access the source code, make any changes or modifications they need, and freely share these changes back to the community at large.
OpenStack is made up of many different moving parts. Because of its open nature, anyone can add additional components to OpenStack to help it to meet their needs.
The OpenStack community has collaboratively identified nine key components that are a part of the core of OpenStack, which are distributed as part of any OpenStack system:
-
- Nova is the primary computing engine behind OpenStack. It is used for deploying and managing large numbers of virtual machines and other instances to handle computing tasks.
- Swift is a storage system for objects and files. It is open-source software designed to manage the storage of large amounts of data cost-effectively on a long-term basis across clusters of standard server hardware. The OpenStack Swift project team works on storage capabilities, drivers and bug fixes designed to improve the performance, stability, reliability, scalability and usability of the object storage software.
- Cinder is a block storage component, which is more analogous to the traditional notion of a computer being able to access specific locations on a disk drive. This more traditional way of accessing files might be important in scenarios in which data access speed is the most important consideration.
- Neutron provides the networking capability for OpenStack. It helps to ensure that each of the components of an OpenStack deployment can communicate with one another quickly and efficiently.
- Horizon is the dashboard behind OpenStack. It is the only graphical interface of OpenStack. The dashboard provides system administrators a look at what is going on in the cloud and to manage it as needed.
- Keystone provides identity services for OpenStack. It is essentially a central list of all of the users of the OpenStack cloud, mapped against all of the services provided by the cloud, which they have permission to use. Developers can easily map their existing user access methods against Keystone.
- Glance provides image services to OpenStack. In this case, “images” refers to images (or virtual copies) of hard disks. Glance allows these images to be used as templates when deploying new virtual machine instances.
- Ceilometer provides telemetry services, which allow the cloud to provide billing services to individual users of the cloud. It efficiently collects, normalizes and transforms data produced by OpenStack services. Its primary targets are monitoring and metering, but the framework is expandable to collect usage for other needs.
- Heat is the orchestration component of OpenStack, which allows developers to store the requirements of a cloud application in a file that defines what resources are necessary for that application. In this way, it helps to manage the infrastructure needed for a cloud service to run.
OpenStack is a cloud operating system that controls large pools of compute, storage and networking resources throughout a datacenter, all managed and provisioned through APIs with common authentication mechanisms. Beyond standard infrastructure as a service functionality, additional components provide orchestration, fault management and service management amongst other services.
P
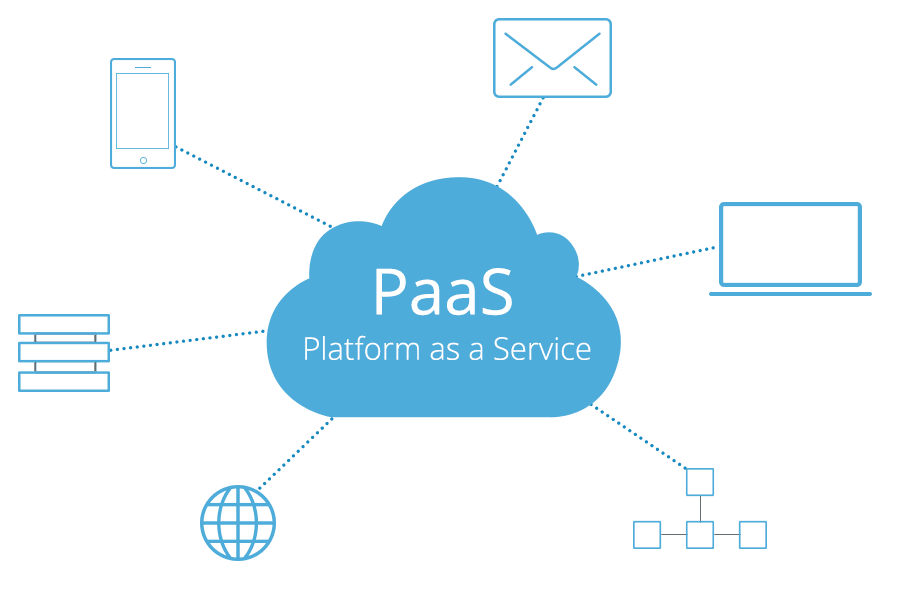
Platform as a Service (PaaS) is a cloud computing model in which a third-party provider delivers hardware and software tools that are usually needed for application development to users over the internet. A PaaS provider hosts the hardware and software on its own infrastructure. As a result, PaaS frees developers from having to install in-house hardware and software to develop or run a new application. As the name suggests, PaaS provides a platform to develop or specialize applications. PaaS allows for the quick, simple and low cost development, testing and integration of applications.
PaaS does not typically replace a business’s entire IT infrastructure. Instead, it tends to incorporate various underlying cloud infrastructure components such as operating systems, servers, databases, middleware, networking equipment and storage services. Each of these functions is owned, operated, configured and maintained by the service provider. PaaS also provides additional resources including database management systems, programming languages, libraries and various development tools. A PaaS provider builds and supplies a resilient and optimized environment on which users can install applications and data sets. Users can focus on creating and running applications rather than constructing and maintaining the underlying infrastructure and services. Many PaaS products are geared toward software development. These platforms offer compute and storage infrastructures, as well as text editing, version management, compiling and testing services that help developers create new software more quickly and efficiently. PaaS can be delivered through public, private and hybrid clouds. PaaS includes development team collaboration, application design and development, application testing and deployment, web service integration, information security and database integration.
Various types of PaaS are available to developers:
Public PaaS is best fit for use in the public cloud. A public PaaS allows the user to control software deployment while the cloud provider manages the delivery of all other major IT components necessary to the hosting of applications, including operating systems, databases, servers and storage system networks. Public PaaS vendors offer middleware that enables developers to set up, configure and control servers and databases without the necessity of setting up the infrastructure side of things.
Private PaaS aims to deliver the agility of public PaaS while maintaining the security, compliance, benefits and potentially lower costs of the private data center. A private PaaS is usually delivered as an appliance or software within the user’s firewall which is frequently maintained in the company’s on-premise data center. A private PaaS can be developed on any type of infrastructure and can work within the company’s specific private cloud. Private PaaS allows an organization to better serve developers and improve the use of internal resources. Private PaaS allows developers to deploy and manage their company’s applications while also abiding by strict security and privacy requirements.
Hybrid PaaS combines public PaaS and private PaaS to provide companies with the flexibility of infinite capacity provided by a public PaaS and the cost efficiencies of owning an internal infrastructure in private PaaS.
Communication PaaS (CPaaS) is a cloud based platform that allows developers to add real time communications to their apps without the need for back-end infrastructure and interfaces. Real time communications occur in apps that are built specifically for these functions. Examples include applications such as Skype, FaceTime and WhatsApp.
CPaaS provides a complete development framework for the creation of real time communications features without the necessity of a developer building their own framework, including standards-based application programming interfaces, software tools, prebuilt apps and sample code.
CPaaS providers also help users throughout the development process by providing support and product documentation. Some providers also offer software development kits as well as libraries that can help build applications on different desktop and mobile platforms.
Mobile PaaS (mPaaS) is the use of a paid integrated development environment for the configuration of mobile apps. In an mPaaS, coding skills are not required. MPaaS is delivered through a web browser and typically supports public cloud, private cloud and on-premise storage. The service is usually leased with pricing per month, varying according to the number of included devices and supported features. MPaaS usually provides an object-oriented drag-and-drop interface which allows users to simplify the development of HTML5 or native apps through direct access to features such as the device’s GPS, sensors, cameras and microphone.
OpenPaaS is a free, open-source, business-oriented collaboration platform that is attractive on all devices and provides useful web apps, including calendar, contacts and mail applications. OpenPaaS was designed to allow users to quickly deploy new applications with the goal of developing a PaaS technology that is committed to enterprise collaborative applications, specifically those deployed on hybrid clouds.
PaaS solutions are frequently used in the development of mobile applications. However, many developers and companies also use PaaS to build cross-platform apps since it provides a flexible and dynamic solution that has the ability to create an application which can be operated on almost any device. Another use of PaaS is in DevOps tools. PaaS provides application lifecycle management features as well as specific features to fit a company’s product development methodologies. The model also allows DevOps teams to insert cloud based continuous integration tools that add updates without producing downtime.
PaaS can also be used to reduce an application’s time to market by automating or completely eliminating housekeeping and maintenance tasks. Additionally, PaaS can decrease infrastructure management by helping to reduce the burden of managing scalable infrastructure. PaaS removes the complexities of load balancing, scaling and distributing new dependent services. Instead of developers controlling these tasks, the PaaS providers take responsibility.

Pay as you go (PAYG) is a payment method for cloud computing that charges based on usage.
Typical contracts can be likened to mobile phone service subscriptions. Users pay for a certain level of service and if they exceed usage they might have to pay additional fees not covered by the subscription or upgrade their subscription. The pay as you go method can be likened to the utility bill. In the pay as you go method, just as in the utility bill, the invoice changes according to the amount of cloud computing services used every month.
There are various advantages of the pay as you go method compared to other cloud computing service contracts.
By paying only for the data used, the pay as you go method saves money. A pre-determined and simple contract provides users with peace of mind. The flexibility and scalability this method provides is adaptable to fluctuations and growth. A non-flexible contract might cause problems if the user’s work plan were to expand, whereas pay as you go method provides users with flexibility.

Private cloud is defined as computing services offered either over the internet or a private internal network and only to select users. Also called an internal or corporate cloud, private cloud computing gives businesses many of the benefits of a public cloud, including self-service, scalability, and elasticity, with the additional control and customization available from dedicated resources over a computing infrastructure hosted on-premise.
A private cloud is a single-tenant environment, meaning the organization using it (the tenant) does not share resources with other users. Those resources can be hosted and managed in a variety of ways.
Private cloud is the second of cloud models which can be public, private, hybrid, multicloud or any combination of the three. All models share common basic elements of cloud infrastructure such as requiring an operating system, however various types of software, such as virtualization, stacked on top of the operating system is what determines how the cloud will function and distinguishes the models.
The main advantage of a private cloud is that users do not share resources. Because of its proprietary nature, a private cloud computing model is best for businesses with dynamic or unpredictable computing needs that require direct control over their environments, typically to meet security, business governance or regulatory compliance requirements. In addition to these benefits private clouds are also preferred for:
- Increased security of an isolated network.
- Increased performance due to resources being solely dedicated to one organization.
- Increased capability for customization.

Public cloud is a platform that uses the standard cloud computing model to make resources such as virtual machines, applications or storage, available to users remotely. In short it is a type of computing in which a service provider makes resources available to the public via the internet. Public cloud services may be free or offered through a variety of subscription or on demand pricing schemes, including a pay-per-usage model.
A public cloud is a fully virtualized environment. In addition, providers have a multi-tenant architecture that enables users or tenants to share computing resources. Each tenant’s data in the public cloud, however, remains isolated from other tenants. Public cloud also relies on high-bandwidth network connectivity to rapidly transmit data. Public cloud architecture can be further categorized by service model. Common service models include SaaS, IaaS and PaaS.
In general, the public cloud is seen as a way for enterprises to scale IT resources on demand, without having to maintain as many infrastructure components, applications or development resources in-house. The pay-per-usage pricing structure offered by most public cloud providers is also seen by some enterprises as an attractive and more flexible financial model. For example, organizations account for their public cloud service as an operational or variable cost rather than capital or fixed costs. In some cases, this means organizations do not require lengthy reviews or advanced budget planning for public cloud decisions.
Because of the multi-tenant nature of public cloud, security is an ongoing concern for some enterprises. Public cloud providers offer security services and technologies, such as encryption, and identity and access management tools. However, it is the enterprise’s responsibility to implement such offerings and use best practices to protect their data. A shared-responsibility model helps identify which components are the responsibilities of the cloud vendor and which should be secured by the user.
Q

Quality Assurance (QA) is the activity of ensuring that a company provides the best possible product or service to the customer. QA is a systematic approach that oversees all phases of a product and prevents future mistakes. This systematic approach is a feedback loop that involves comparison with standards, monitoring of processes and mistake prevention.
The ISO (International Organization for Standardization) is a driving force behind QA practices and mapping the processes used to implement QA. Many companies use ISO 9000 to ensure that their quality assurance system is in place and effective.
QA helps a company create products and services that meet the needs, expectations and requirements of customers. It yields high-quality product offerings that build trust and loyalty with customers. The standards and procedures defined by a quality assurance program help prevent product defects before they arise.
Software quality assurance (SQA) systematically finds patterns and the actions needed to improve development cycles. SQA has become important for developers as a means of avoiding errors before they occur, saving development time and expenses. There have been numerous SQA strategies. Each development process seeks to optimize work efficiency.
R

RecoverPoint for Virtual Machines® is a virtualized solution that provides data replication, protection and recovery in the VMware vSphere environment. It enables quick recovery of VMware virtual machines to any point-in-time. Dell EMC RecoverPoint for Virtual Machines® provides continuous data protection for operational and disaster recovery. This way virtual machine protection can be managed simply and efficiently.
Enterprise application owners can set and manage their VM data protection through a plug-in to VMware vCenter. Automated provisioning makes it easier to meet your recovery point and recovery time objectives.
RecoverPoint for Virtual Machines is hypervisor based, software-only data replication that integrates with customer supplied VMware vCenter. RecoverPoint for Virtual Machines supports replication policies over any distance; synchronous, asynchronous or dynamic, and optimizes WAN bandwidth use with data compression and deduplication.
S

Software as a Service (SaaS) is a cloud based service where instead of downloading software you instead access an application via an web browser to run and update it. SaaS is the largest cloud market of today and is still growing fast. SaaS eliminates the requirement to install and run applications to computers one by one thanks to its software distribution model. SaaS is closely related to the application service provider (ASP) and on demand computing software delivery models. In the software on demand SaaS model, the provider gives customers network-based access to a single copy of an application that the provider created specifically for SaaS distribution. The application’s source code is the same for all customers and when new features or functionalities are rolled out, they are rolled out to all customers. Organizations can integrate SaaS applications with other software using application programming interfaces (APIs). For example, a business can write its own software tools and use the SaaS provider’s APIs to integrate those tools with the SaaS offering. There are SaaS applications for fundamental business technologies such as email, sales management, customer relationship management (CRM), financial management, human resource management, billing and collaboration.
The biggest advantage of SaaS is that it removes the need for organizations to install and run applications on their own computers or in their own data centers. This eliminates the expense of hardware acquisition, provisioning and maintenance, as well as software licensing, installation and support. Other benefits of the SaaS model include:
- Flexible payments: Rather than purchasing software to install, or additional hardware to support it, customers subscribe to a SaaS offering. Generally, they pay for this service on a monthly basis using a pay-as-you-go model. Transitioning costs to a recurring operating expense allows many businesses to exercise better and more predictable budgeting. Users can also terminate SaaS offerings at any time to stop those recurring costs. It also reduces the burden on in-house IT staff.
- Scalable usage: Cloud services like SaaS offer high vertical scalability, which gives customers the option to access more or fewer services or features on demand.
- Accessibility and persistence: Since SaaS applications are delivered over the internet, users can access them from any internet-enabled device and location. As any SaaS application can run on a web browser it does not matter which operating system, such as Windows, Mac, Linux, Android or iOS, is used.
SAP Cloud Platform (SCP) is a platform-as-a-service (PaaS) product that provides a development and runtime environment for cloud applications. SAP HANA (high-performance analytic appliance) is an in-memory database and application development platform for processing high volumes of data in real time. Using open-source and open standards, SAP HANA allows independent software vendors and developers to create and test HANA based cloud applications. The in-memory computing engine allows HANA to process data stored in RAM instead of reading data from the disk. This allows the application to obtain real time results for client operations and data analytics.
SAP HANA as a service refers to a fully managed SAP HANA service. It is a solution that delivers the development, test and live environment customers need for SAP HANA installed in a timely manner. The only thing the customer needs to do is to decide what kind of functionalities they require and where these should be stored. Other administrative tasks such as installation, backup and upgrade are also included in SAP HANA as a service. This service provides advantages by reducing project times due to its high availability rate and fast installation.
Scalability is the capability of a process, network, software or appliance to grow and manage increased demands. This is one of the most valuable and predominant feature of cloud computing. Through scalability you can scale up your data storage capacity or scale it down to meet the demands of your growing business. When business demands are increasing, you can easily add nodes to increase your storage space or you can increase the number of servers currently used. When the increased demand is reduced then you can move back to your original configuration.
Scalability enables you to accommodate larger workloads without disruption or complete transformation of existing infrastructure. To effectively leverage scalability you need to understand the complexity and the types of scalability.
Vertical Scaling: Vertical scaling is the capability to add resources to accommodate increasing workload volumes. It can be done by moving the application to bigger virtual machines deployed in the cloud or you can scale up by adding expansion units as well with your current infrastructure. The downside to scaling up is that it increases storage capacity but the performance is reduced because the compute capacity remains the same.
Horizontal Scaling: Horizontal Scaling is the addition of nodes to the existing infrastructure to accommodate additional workload volumes. Contrary to vertical scaling, it also delivers performance along with storage capacity. The total workload volume is aggregated over the total number of nodes and latency is effectively reduced. This scaling is ideal for workloads that require reduced latency and optimized throughput.
Diagonal Scaling: Diagonal scaling is the combination of vertical and horizontal scaling. It removes storage resources as requirements decrease. Diagonal scaling delivers flexibility for workload that requires additional storage resources for specific instances of time. For instance, a website sets up diagonal scaling; as the traffic increases, the compute requirements are accommodated. As the traffic decreases, the computation capacity is restored to its original size. This type of scaling introduces enhanced budgeting and cost effectiveness for environments and businesses dealing with variable workload volumes.

Security Operation Center (SOC) is a facility that houses an information security team responsible for monitoring and analyzing an organization’s security posture on an ongoing basis. The SOC team’s goal is to detect, analyze and respond to cyber security incidents using a combination of technology solutions and a strong set of processes. Security operations centers are typically staffed with security analysts and engineers as well as managers who oversee security operations. SOC staff work close with organizational incident response teams to ensure security issues are addressed quickly upon discovery.
Rather than being focused on developing security strategy, designing security architecture or implementing protective measures, the SOC team is responsible for the ongoing, operational component of enterprise information security. Security operations center staff is comprised primarily of security analysts who work together to detect, analyze, respond to, report on and prevent cyber security incidents. Additional capabilities of some SOCs can include advanced forensic analysis, cryptanalysis and malware reverse engineering to analyze incidents.
The first step in establishing an organization’s SOC is to clearly define a strategy that incorporates business-specific goals from various departments as well as input and support from executives. Once the strategy has been developed, the infrastructure required to support that strategy must be implemented. The security operations center also monitors networks and endpoints for vulnerabilities in order to protect sensitive data and comply with industry or government regulations.
The key benefit of having a security operations center is the improvement of security incident detection through continuous monitoring and analysis of data activity. By analyzing this activity across an organization’s networks, endpoints, servers and databases around the clock, SOC teams are critical in ensuring timely detection and response of security incidents. The 24/7 monitoring provided by a SOC gives organizations an advantage to defend against incidents and intrusions regardless of source, time of day, or attack type. Security operations center helps to close the gap between attackers’ time to compromise and enterprises’ time to detection, and stay on top of the threats.
Software-defined data center (SDDC) is the phrase used to refer to a data center where the whole infrastructure is virtualized and delivered as a service. Control of the data center is fully automated by software. Unlike traditional data centers hardware configuration is maintained through intelligent software systems. Software-defined data centers are considered by many to be the next step in the evolution of virtualization and cloud computing as it provides a solution to support both legacy enterprise applications and new cloud computing services.
Virtualization is the core of the software-defined data center. There are three core components of the software-defined data center, which are network virtualization, storage virtualization and server virtualization:
Network virtualization combines the available resources in a network by splitting up the available bandwidth into channels, each of which can be assigned to a particular server or device in real time.
Storage virtualization is the pooling of physical storage from multiple storage devices into what appears to be a single storage device.
Server virtualization is the partitioning of a physical server into smaller virtual servers to help maximize your server resources. In server virtualization the resources of the server itself are hidden or masked from users, and software is used to divide the physical server into multiple virtual environments, called virtual or private servers.
Software-defined data center applications allow for dynamic structuring of the infrastructure and IT resources.
Software-defined storage (SDS) is a storage architecture that separates storage software from its hardware. Unlike traditional network-attached storage (NAS) or storage area network (SAN) systems, SDS is generally designed to perform on any industry-standard or x86 system, removing the software’s dependence on proprietary hardware. Software-defined storage (SDS) allows for greater flexibility, efficiency and scalability by making storage resources of users and organizations programmable. This approach enables storage resources to be an integral part of a larger software-designed data center (SDDC) architecture, in which resources can be easily automated and orchestrated.
Software defined storage usually has the following features:
- Automation: Simplified management that keeps costs down.
- Standard interfaces: An application programming interface (API) for management and maintenance of storage devices and services.
- A virtualized data path: Block, file and object interfaces that support applications written to these interfaces.
- Scalability: The ability to scale out storage infrastructure without impeding performance.
- Transparency: The ability to monitor and manage storage use while knowing what resources are available and at what costs.
SDS does not separate the storage itself from the hardware. It provides many services using industry-standard servers instead of proprietary hardware. Basically, SDS abstracts the things that control storage requests, not what’s actually stored. It allows to o manipulate how and where data is stored.
SDS can run on any industry-standard servers and disks. Unlike other types of storage, SDS depends more on its own software than the hardware it sits on. This means SDS can run both on the server’s standard operating system and in a virtual machine. Some SDS products can even run across containers.
T
Test includes a series of activities designed to determine the quality of the developed software and detect errors in the software so that the product can be corrected before it is released. In simple terms it is an activity to control whether the actual results match the expected results and ensure the software system is free of errors. Software testing is more than just error detection. Test is also done to ensure that the product functions as the end user expects.
Development is the process of writing and maintaining the source code that results in a product. Software development may include research, prototyping, modification, reuse, re-engineering and maintenance. The process of software development is a comprehensive activity that ranges from the initial design to the final test.
The process of creating software is known as software development. Software testing is done with the intent of finding errors and whether the specified requirements are met.
Software development contains the code writing process, whereas testing is used for determining whether the code runs as planned. In short, software development includes a series of computer science activities that includes software creation, design, distribution and support. Software testing is an assessment to inform the concerned customer about the product’s or software’s quality.
There are 4 different levels of certification determined by the Uptime Institute, which are internationally valid and focus on the capacity, redundancy and fault tolerance of a data center or IT infrastructure facility. In order to obtain Tier certificates, the technical requirements of each level must be fulfilled.
Uptime Institute TIER Comparison Table
| Tier I | Tier II | Tier III | Tier IV | |
| Building Type | Dependant | Dependant | Independant | Independant |
| Support Shift | None | 1 | More than 1 | 24 hour support |
| Standard Energy Per Cabinet | < 1 kW | 1-2 kW | 1-2 kW | 1-3 kW |
| Maximum Energy per Cabinet | < 1 kW | 1-2 kW | > 3 kW | > 4 kW |
| Raised Floor Height | 12” | 18” | 30-36” | 30-42” |
| Capacity of Components Supporting the IT Load | N | N + 1 | N + 1 | N + any fault |
| Redundancy | None | Yes | Yes | Yes |
| Power Distribution Channels | 1 | 1 | 1 active, 1 alternative | 2 simultaneously active |
| Concurrent Maintenance | No | No | Yes | Yes |
| Max. Permitted Outage Time | 28,8 hour | 22 hour | 1,6 hour | 0,8 hour |
| Uptime | % 99,67 | % 99,75 | % 99,98 | % 99,99 |
V

Virtualization is the creation of a virtual version of a server, desktop, storage device, operating system or network resource. In other words, virtualization is a technique, which allows sharing a single physical instance of a resource or an application among multiple customers and organizations. There are different types of virtualization:
Hardware Virtualization: Creation of a virtual machine over existing operating system and hardware is known as hardware virtualization. A virtual machine provides an environment that is logically separated from the underlying hardware.
The installation of the virtual machine software or virtual machine manager directly on the hardware system is known as hardware virtualization. After the virtualization of hardware system one can install different operating system on it and run different applications on those operating systems. Hardware virtualization is mainly done for the server platforms, because controlling virtual machines is much easier than controlling a physical server.
Operating System Virtualization: Installation of the virtual machine software or virtual machine manager on the host operating system instead of directly on the hardware system is known as operating system virtualization. Operating system virtualization is mainly used for testing the applications on different platforms of operating systems.
Server Virtualization: Installation of the virtual machine software or virtual machine manager on the Server system is known as server virtualization. Server virtualization is used for when a single physical server needs to be divided into multiple servers for balancing the load.
Storage Virtualization: Storage virtualization is the process of grouping the physical storage from multiple network storage devices. Storage virtualization is also implemented by using software applications. Storage virtualization is mainly done for backup and recovery purposes.
A virtual CPU (vCPU), also known as a virtual processor, is a physical central processing unit (CPU) that is assigned to a virtual machine.
Virtual machines are allocated one vCPU each by default. If the physical host has multiple CPU cores at its disposal, however, then a CPU scheduler assigns execution contexts and the vCPU essentially becomes a series of time slots on logical processors. In this regard some experts treat vCPU not as a separate CPU but a share of the time the core of the processer is used.
Because processing time is billable, it is important for an administrator to understand how his cloud provider documents vCPU usage in an invoice. It is also important for the administrator to realize that adding more vCPUs will not automatically improve performance. This is because as the number of vCPUs goes up, it becomes more difficult for the scheduler to coordinate time slots on the physical CPUs, and the wait time can degrade performance.
In VMware, vCPUs are part of the symmetric multi-processing (SMP) multi-threaded compute model. SMP also allows threads to be split across multiple physical or logical cores to improve performance of more parallel virtualized tasks. vCPUs permit multitasking to be performed sequentially in a multi-core environment.
Virtual hard disk (VHD) is a disk image file format for storing the complete contents of a hard drive. The disk image, sometimes called a virtual machine, replicates an existing hard drive and includes all data and structural elements. It can be stored anywhere the physical host can access
There are two main types of virtual hard disks: fixed-size and dynamically expanding. Both types have a maximum size value that specifies how large the disk will appear to virtual machines. However, fixed-size VHDs will automatically take up the specified amount of physical disk space on the host computer’s file system, whereas dynamically expanding disks will allocate space only as needed.
In most circumstances it is best to configure virtual machines to use virtual hard disk instead of physical hard disks. A virtual disk is a file or set of files that appears as a physical disk drive to a guest operating system. When you configure a virtual machine with a virtual disk, you can install a new operating system onto the virtual disk without repartitioning a physical disk or rebooting the host. A key advantage of virtual disks is their portability. Because the virtual disks are stored as files on the host machine or a remote computer, you can move them easily to a new location on the same computer or to a different computer.







